
* 위 참고도서를 직접 구입해 개인적으로
공부한 내용을 공유합니다.
ADsP를 준비하시는 많은 비전공자 분들에게
도움이 되었으면 합니다 :)
* 이 포스팅은 PC 버전에 최적화 되어있습니다.
기출 빈도 상 중 하
* Part3 데이터 분석은
교재에 명시된 기출문제 위주로
주요 R언어 문법 및 함수 사용법을 다루고자 합니다.
1. 데이터 마이닝 개요
'데이터마이닝' 이란 거대한 양의 데이터 속에서 쉽게 드러나지 않는 유용한 정보를 찾아내는 과정
(1) 분류(classfication) : 새롭게 나타난 현상을 검토하여 기존의 분류, 정의된 집합에 배정하는 것. 예) 의사결정나무
(2) 추정(Estimation) : 주어진 입력 데이터를 사용하여 알려지지 않는 결과의 값을 추정. 예) 신경망 모형
(3) 예측(Prediction) : 미래의 양상 또는 값을 추정 + 분류, 추정의 의미 포함함. 예) 의사결정나무, 신경망, 장바구니 분석 등
(4) 연관분석(Association) : '함께 팔리는 물건'과 같이 아이템의 연관성을 파악. 예) 장바구니 분석
(5) 군집(Clustering) : 분류와 달리 미리 정의된 기준이나 예시에 의해서가 아니라 데이터 자체의 유사성 및 이질성에 의해 군집화됨.
(6) 기술(Description) : 데이터가 암시하는 바에 대해 설명이 가능해야 함.
2. 분류 분석
1) 로지스틱 회귀모형
- 로지스틱 회귀 분석 : 반응형 변수가 범주형인 경우에 적용되는 회귀분석 모형 → 성공 또는 실패, 흡연 또는 비흡연과 같은 두 가지 범주로 나누어져 있을 때, 이항 분포를 따르는 경우 사용되는 통계 기법, 일반화 선형모델이라고도 함(Generalized linear model, GLM)
- 선호되는 이유 : 독립변수에 대해서 어떠한 가정도 필요로 하지 않고, 독립변수가 연속형 및 이산형 두 경우 모두 가능함. 범주형 변수일 때는 선형회귀모델을 그대로 적용할 수 없기에 로지스틱 회귀분석이 제안됨.
- 오즈비(odds ratio) = 성공률/실패율 = P/(1-P),
단 P가 성공률 → 성공 가능성이 높을 경우 1보다 큼, 실패 가능성이 높을 경우 1보다 작음
- glm 함수 사용 : glm(모형, data, family = "binominal"), 과산포가 있을 경우 quasibinominal 사용
* y= e(a+bx), x의 회귀계수는 eb 배 증가
예시) glm 후 summary에서 coefficients가 5가 나올경우 x가 1 증가할 때 e5 배 됨
* 최대우도추정법 : 관측값들이 가정된 모집단에서 하나의 표본으로 추출될 가능성이 가장 크게 되도록 하는 회귀계수 추정 방법. 로지스틱회귀분석에서 이 방법을 사용하여 회귀방정식을 추정함
- 다항 로지스틱 회귀분석 시, anova 함수를 통해 모형의 적합단계별로 이탈도와 감소량과 유의성 검정결과를 제시해줌 * null adeviane와 residual diviance 차이는 해당 변수가 모델에 포함 되었을 때 모델의 성능이 얼마나 나아지는지를 보여주는 수치임
2) 신경망 모형
(1) 인공신경망(Artificial neuron Network)
: 신경망 모형은 지도학습의 한 방법으로 이메일을 스팸과 스팸 아님으로 분류, 불만이 많은 고객과 만족하는 고객으로 분류할 때 사용.
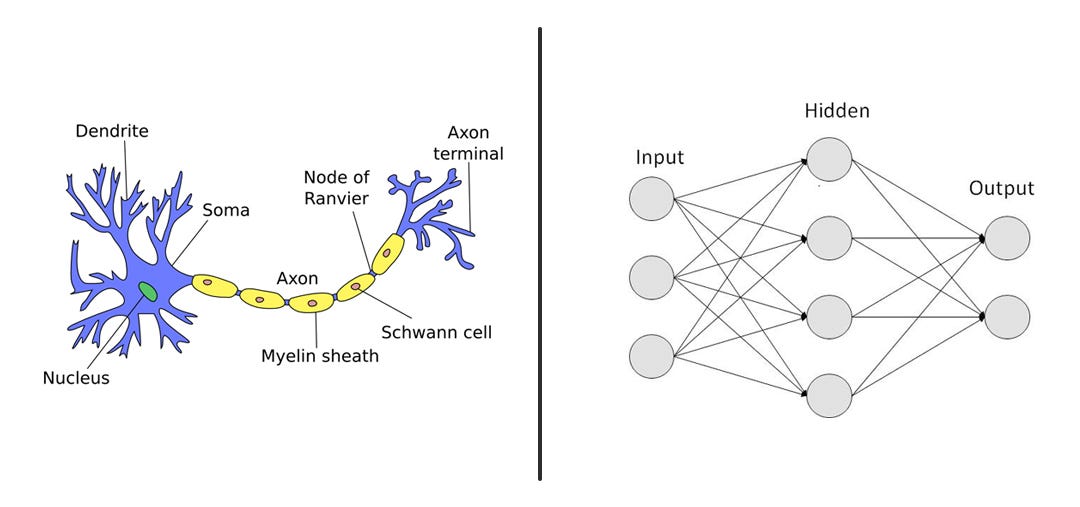
- 신경망 모델 : 뉴런 간의 신호전달 시스템을 모사.
입력이 주어지면 신경망 모델의 화살표를 따라 hidden layer에 도달하고 이 hidden layer의 노드는 주어진 입력에 따라 활성화. 이는 다시 hidden layer 노드가 출력값을 계산해 그 결과를 출력층에 전달하는 방식임

- 역전파 알고리즘 : 맨 뒷단에 있는 에러를 앞으로 전달 시키는 형태. 입력데이터와 그 데이터와 연결된 레이블, 출력의 오차값을 알아야 학습이 가능했기 때문인데, hidden layer 부분에 출력 오차값을 얻어낼 수 없었음. 따라서 출력단에서 역으로 오차를 추정해서 가중치를 조정하는 방식.
* R에서 neuralnet( ), nnet( )함수 활용

(2) 신경망 학습은 가중치의 조절 작업
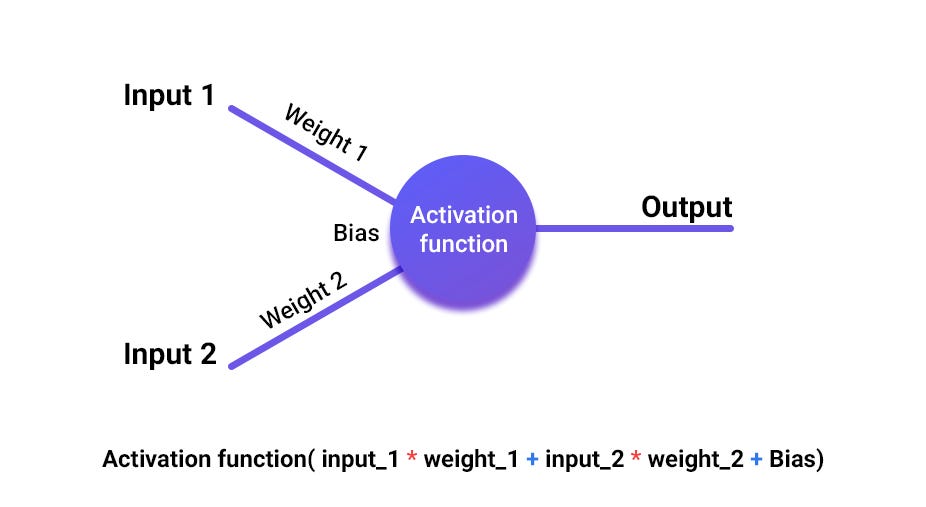
- input과 output이 있을 때, input을 input layer에 준 다음 모델의 output이 원하는 output과 같은지 확인한다. 값이 다를 경우 가중치를 조절한다.
- 여기서 f는 활성함수로 결과의 점위를 제한하고 계산의 편의성을 제공함. 시그모이드 함수, 부호 함수, 소프트 맥스 함수 등이 있음.
(3) 신경망의 hidden layer 및 은닉 노드 수를 정할 때 고려해야 할 사항
a. 다층신경망은 단층신경망에 비해 훈련이 어렵다
b. 노드가 많을수록 복잡성을 잡아내기 쉽지만, 과적합의 가능성도 높아진다.
c. 은닉층 노드가 너무 적으면 복잡한 의사결정 경계를 만들 수 없다.
d. 출력층 노드의 수는 출력 범주의 수로 결정, 입력의 수는 입력 차원의 수로 결정한다.
(4) 신경망 모형의 장단점
3) 의사결정나무 모형
(1) 의사결정나무 : 의사 결정 규칙을 나무 구조로 나타내어 전체 자료를 몇 개의 소집단으로 분류하거나 예측을 수행하는 분석방법
* 의사결정나무 분석 패키지
a. tree 패키지, rpart 패키지 : 엔트로피, 지니 지수를 기준으로 가지치기를 할 변수를 결정하기 때문에 상대적으로 연산 속도는 빠르지만 과적합화의 위험성이 존재. 그래서 두 패키지를 사용할 경우에는 가지치기 과정이 필요.
b. party패키지 : p-test를 거친 significance를 기준으로 가지치기를 할 변수를 결정하기 때문에 biased될 위험이 없어 별도로 가지키기 할 필요가 없다는 장점이 있음. 단, 입력 변수의 레벨이 31개까지로 제한
(2) 데이터 분할과 과대적합 : training/test set으로 나누어 사용. 과대적합이나 과소적합의 문제를 높이기 위해서는 다양한 데이터를 확보하고, 확보한 데이터로부터 더 다양한 특징을 찾아서 학습에 사용해야 함.
(3) 의사결정나무 구분
a. 분류나무 : 목표변수가 이산형인 경우, 분류변수와 분류 기준값의 선택방법으로 카이제곱통계량의 p값은 클수록, 지니지수와 엔트로피 지수는 그 값이 작은 방향으로 가지분할을 수행.
* 불확실성 측정 지표
- 지니 지수 : 불순도 혹은 다양성을 계산하는 방법
- 엔트로피 지수 : 지니 지수와 비슷한 개념이지만, log를 포함시킴으로써 정규화 하는 과정을 거침.
→ 두 지수 모두 작을 수록 좋음
b. 회귀나무 : 목표변수가 연속형인 경우, F통계량의 p값이 작아지는 방향으로, 분산의 감소량이 최대화되는 방향으로 가지분할이 수행됨.
* 정지규칙 : 더 이상 분리가 일어나지 않고 현재의 마디가 최종마디가 되도록하는 여러가지 규칙(자식마디의 초소 관측치 수, 카이제곱통계량, 지니 지수, 엔트로피 지수 등)
* 가지치기 : 최종 마디가 너무 많으면 모형이 과대적합된 상태로, 분류된 관측치의 비율, MSE 등을 고려하여 수준의 가지치기 규칙을 제공해야 함.
c. 의사결정나무 알고리즘 분류 및 기준변수의 선택법
(4) 의사결정나무 장단점
* 의사결정나무는 상대적으로 모델이 불안정해서 Bootstrapping, bagging 등의 방법으로 사용. 고객 타겟팅, 고객들의 신용점수화, 캠페인 반응분석, 고객행동예측, 고객 세분화 등이 있음.
2. 분류 분석
4) 앙상블 모형
- 여러 개의 분류모형에 의한 결과를 종합해 분류의 정확도를 높이는 방법으로 과적합 모델에 사용하기 좋음
(1) 배깅(bagging) : bootstrap aggregation의 준말.
- train data를 모집단으로 생각하고 크기가 같은 표본을 여러 번 단순 임의 복원추출 → 각 bootstrap 표본에 대해 분류기를 생성한 후 → 그 결과를 앙상블
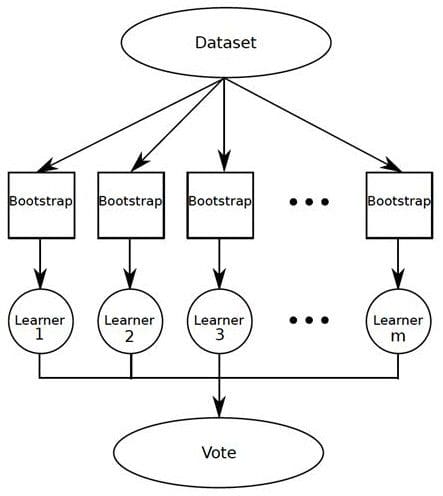
(2) 부스팅(booting) : 배깅과 유사하나 bootstrap 표
본을 구성하는 샘플링 과정에서 분류가 잘못된 데이터에 더 큰 가중치를 주어 표본을 추출하는 방식.
(3) 랜덤 포레스트(random forest) : 배깅에 랜덤과정을 추가한 방법. 의사결정나무의 과적합 문제를 해결하는 대안으로써 활용.
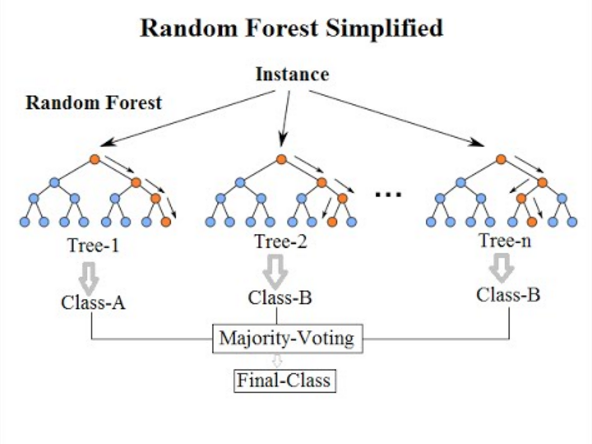
- 의사결정나무들이 모여서 그 결과를 결합하며, 각 의사결정나무를 만들 때 사용하는 변수들을 임의로 추출하는 방식
5) 서포트 벡터 머신(SVM, Support Vector Machine)

- 서로 다른 분류에 속한 데이터 간의 간격이 최대가 되는 선을 찾아 이를 기준으로 데이트를 분류
- Kerlab, e1070 패키지 활용하며 svm( )함수 사용
- 특히 패턴 인식 분야(안면 인식 등)에 활용됨
- Cost를 사용해 과적합(overfitting)정도를 조절
- SVM 모델의 장단점
6) 나이브 베이즈 분류 모형
- 베이즈 정리에 기반한 방법으로 사후확률은 사전확률을 통해 예측할 수 있다는데 기반한 분류 모형
- 스팸메일 분류 시, 고객 취향 맞춤 상품 추천 시 활용
- naiveBayes(모형, data) 함수 사용
* 베이즈 정리
- 이전 경험과 현재의 증거를 토대로 어떤 사건의 확률을 추론하는 과정
- 사전확률과 사후확률사이의 관계를 조건부 확률을 이용하여 계산
- 결과를 관측한 뒤 원인을 추론
* 나이브 베이즈 분류모형 장단점
7) 모형 평가 (기출빈도 높음!)
- 적합한 모델을 선택하기 위한 기준
a. 일반화의 가능성 : 같은 모집단 내의 다른 데이터에 적용할 경우에도 안정적인 결과를 제공하는가?
b. 효율성 : 분류분석 모형이 얼마나 효과적으로 구축되었는지를 평가. 적은 입력변수를 필요로 할 수록 효율성이 높음
c. 예측과 분류의 정확성은 실제 문제에 적용했을 때의 정확성을 의미
(1) 홀드아웃(hold-out)방법
: 훈련용 자료(train data(70%))와 검증용 자료(test data(30%))를 랜덤하게 나누어 교차검정을 실시하는 방법. 검증용 자료의 결과는 모형에 영향을 미치지 않고 성과 측정만을 위해 사용
(2) 교차검증(cross-validation)
: 주어진 데이터를 가지고 반복적으로 성과를 측정하여 그 결과를 평균한 것. 대표적으로 k-fold 교차검증 있음.
(3) 붓스트랩
: 훈련용 자료를 반복 재선정, 복원추출법에 기반함. 전체 데이터 양이 크지 않은 경우 적합함
* 0.632 bootstrap : 무작위 표본추출을 반복할 때 평균적으로 초기 표본의 63.2%가 훈련용 집합에 포함되고, 36.8% 가 검증용 집합에 형성됨을 의미
(4) 오분류표(confusion matrix)

a. precision : True로 예측한 것 중 실제 True인 경우의 비율(TP/(TP+FP))
b. accuracy : 전체 예측에서 옳은 예측의 비율
(TP+TN)/(TP+FP+FN+TN)
c. recall(sensitivity) : 실제 True인 것들 중에 True로 예측된 비율 (TP/(TP+FN))
d. specificity : 실제 False인 것들 중에 False로 예측된 비율 (FP/(FP+TN))
e. FR rate : True가 아닌데 True로 예측된 비율
(1-specificity)
f. F1 : precision과 recall의 조화평균. 시스템 성능을 하나의 수치로 표현하기 위해 사용하는 점수로 0~1 사이의 값을 가진다.
(2*[Precision*Recall/(Precision+Recall])
(5) ROC(Receiver Operating Characteristic)
: 레이더 이미지 분석의 성과를 측정하기 위해 개발.
x축에는 FR ratio, y축에는 민감도를 나타내며 ROC그래프의 아래 면적이 넓을수록 좋은 모형으로 평가함.
AUC 값으로 평가. x값이 0이고 y값이 1이면 ACU =1

(6) 이익도표와 향상도
- 이익(gain) : 목표 범주에 속하는 개체들이 각 등급에 얼마나 분포하고 있는지를 나타내는 값
- 이익도표 : 분류분석 모형을 사용해 분류된 관측치가 각 등급별로 얼마나 포함되는지를 나타내는 도표
- 향상도 곡선(lift curve) : 랜덤모델과 비교하여 해당
모델의 성과가 얼마나 향상되었는지를 각 등급별로 파악. 향상도는 모델을 사용하여 얻은 결과와 모델을 사용하지 않고 얻은 결과 사이의 비율로 계산되는 측정값 또는 유효성. performance(data, "lift","rpp") 함수 사용

* 향상도 곡선을 읽는 방법
- X축은 모집단의 비율을 나타내며 가장 높은 확률부터 가장 낮은 확률 순서대로 표시
- Y축은 사용자의 모델이 무작위 모델보다 얼마나 더 좋은지를 보여주며 상위 등급에서 향상도가 매우 크고 하위 등급으로 갈수록 향상도가 감소함. 만약 등급에 관계없이 향상도 차이가 없으면 모형의 예측력이 좋지 않음.
3. 군집분석
- 유사한 성격을 가지는 데이터들 끼리 군집으로 집단화하고, 형성된 군집들의 특성을 파악해 군집들 간의 관계를 분석하는 다변량분석 기법
1) 계층적 군집
- 가장 유사한 개체를 묶어나가는 과정을 반복하여 원하는 개수의 군집을 형성하는 방법. 계통도, 덴드로그램의 형태로 결과가 주어지며 각 개체는 하나의 군집에만 속하게 됨.
- 군집을 형성하는 매 단계에서 지역적(local) 최적화를 수행해나가므로 그 결과가 전역적인(global) 최적해라고 볼 수 없음
* 군집방법
- 병합적 방법 : hclust, cluster 패키지의 agnes( ), mclust( )
a. 단일연결법 : 한 군집의 점과 다른 군집의 점 사이의 가장 짧은 거리를 측정. 고립된 군집을 찾는 데 중점
b. 완전연결법 : 두 군집 사이에 나타날 수 있는 거리의 최대값 측정. 군집들의 내부 응집성에 중점
c. 평균연결법 : 모든 항목에 대한 거리평균 계산. 불필요한 계산량이 많아 질 수 있음
d. 중심연결법 : 두 군집간의 중심거리 측정
e. 와드연결법 : 군집내의 오차제곱합에 기초하여 군집
- 분할적 방법 : cluster 패키지의 diana( ), mona( )
* 거리 측정법
(1) 수학적 거리
a. 유클리드 : 두 점 사이의 거리
b. 맨해튼 : 두 점 좌표간의 절대값 차이, 데이터 이상치사 존재할때 사용
c. 민코프스키
(2) 표준화 거리(통계적 거리) : 각 변수를 해당 변수의 표준편차로 척도 변환한 후에 유클리드 거리를 계산한 거리(관측단위의 영향을 없애기위함)
a. 마할라노비스 : 변수의 표준화와 변수 간의 상관성을 동시에 고려한 통계적 거리
2) 비계층적 군집
(1) k-means 군집
: 원하는 군집 수 k 값을 지정하고, 각 자료들에 가까운 초기값을 할당하여 군집을 형성 → 각 군집의 평균을 재계산하여 초기값을 갱신한 뒤 → 군집의 중심점(평균)으로 부터 오차제곱합이 최소가 되도록 자료를 재배치 → 이를 반복하여 k개의 최종 군집을 형성
* k-means 군집 장단점
3) 혼합분포군집
- k개의 군집을 초기에 형성한 뒤 → 각 자료들이 군집에 포함될 확률을 계산하여 → EM 알고리즘을 통해 추정할 파라미터 기대치를 최대화하여 파라미터를 조절
* EM(Expectation Maxmization) : 주어진 데이터를 가지고 알려지지 않은 분포 파라미터를 예측하고, 그 예측값을 데이터에 재적용하여 기대치를 최대화시키는 과정 반복을 통해 최적 파라미터를 구하는 알고리즘
* k-means vs 혼합분포군집
4) SOM(Self-Organizing Maps) : 자기조직화지도
- 인공 신경망의 한 종류로 차원축소와 군집화를 동시에 수행하는 기법. kohonen 패키지, som( ) 함수 사용
* SOM의 기능
a. 구조 탐색 : 데이터의 특징을 파악하여 유사 데이터를 군집화함. 고차원 데이터셋을 저차원인 맵(2D 그리드에 매핑)에 표현
b. 차원축소 및 시각화 : 차원을 축소하여 2차원 그리드에 매핑하여 인간이 시각적으로 인식할 수 있게 함
* SOM과 신경망 모형의 비교
- 신경망 모형은 연속적인 layer인 반면 SOM은 2차원 그리도로 구성
- 신경망 모형은 에러를 수정하는 학습을 하는 반면 SOM은 경쟁 학습을 시킴.
- 신경망 모형은 지도학습, SOM은 비지도 학습
4. 연관분석
1) 연관규칙
(1) 개념 : 항목들 간의 '조건-결과'식으로 표현되는 유용한 패턴. 이 규칙을 발견해내는 것을 연관분석이라 하며 흔히 장바구니 분석이라고도 함.
예) 기저귀를 사는 고객은 맥주를 동시에 구매
(2) 연관규칙의 측정 지표
a. 지지도 : 상품 A와 B를 동시에 구매할 확률
P(A∩B) = A와 B가 동시에 포함된 거래 수/전체 거래 수
b. 신뢰도 : 상품 A를 포함하는 거래 중 A와 B가 동시에 거래되는 확률로 상품 A를 구매했을 때 상품 B를 구매할 확률 P(A∩B)/P(A) =A와 B가 동시에 거래된 수/A가 포함된 거래 수
c. 향상도 : 상품A 거래 중 B가 포함된 거래의 비율/상품B가 거래된 비율 P(A∩B)/P(A)*P(B)=P(B|A)/P(B)
- 품목 A와 B사이에 아무런 상호 관계가 없으면, 독립인 경우 향상도는 1, 1보다 크거나 작은 경우 상관관계 존재함. 예) A와 B의 향상도가 1보다 클 경우 상품 B를 구입하는 비율보다 A를 구매한 후에 B를 구매할 확률이 더 높다는 것을 의미함
(3) 연관분석 절차
- Apriori 알고리즘 분석 절차 : 최소 지지도를 설정 → 개별 품목 중에서 최소 지지도를 넘는 모든 품목을 찾음 → 찾은 개별 품목만을 이용하여 최소 지지도를 넘는 품목집합들을 하나씩 늘려가며 찾음 → 반복 수행 후 최소 지지도가 넘는 빈발품목집합을 찾음
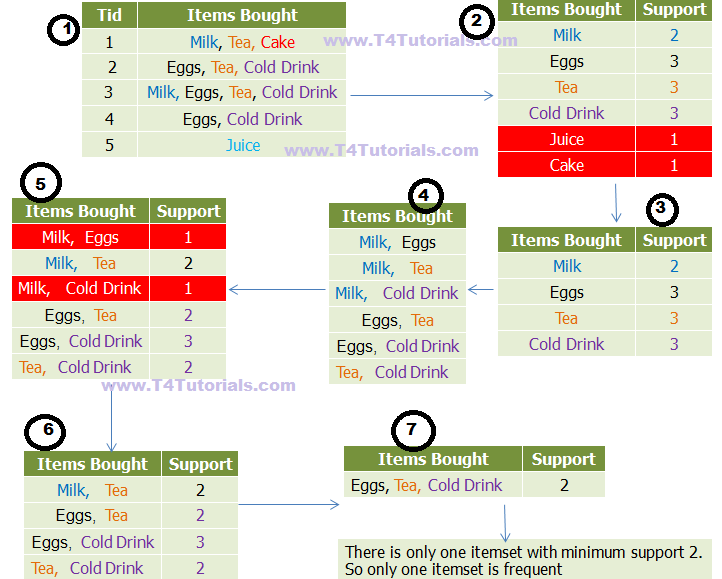
(4) 연관분석의 장단점
'데이터분석 > 데이터분석준전문가(ADsP)' 카테고리의 다른 글
| ADsP 대비 Part3.통계분석 (0) | 2019.05.16 |
|---|---|
| ADsP 대비 Part3.R기초와 데이터 마트 (1) | 2019.05.13 |
| ADsP 대비 Part2.분석 마스터플랜 (0) | 2019.05.13 |
| ADsP 대비 Part2.데이터 분석 기획의 이해 (0) | 2019.05.12 |
| ADsP 대비 Part1.가치창조를 위한 데이터 사이언스와 전략 인사이트 (0) | 2019.04.04 |




댓글