
1) 통계분석 개요
(1) 모집단과 표본
- 모집단: 관심의 대상이 되는 모든 개체의 집합(모평균, 모분산 → 모수(parameter))
- 표본: 모집단에서 분석 대상으로 관찰된 일부의 집합(표본평균, 표본분산 → 통계량(statistic))
(2) 표본 추출 방법(sampling)
a.확률적 추출(probability sampling) : 모집단을 구성하는 개별 개체가 표본으로 선택될 확률이 정해진 경우
- 단순 무작위 추출 : 각 개체가 표본으로 선택될 확률이 동일하게 추출
- 계통 추출 : 모집단의 개체에 1, 2, … N 이라는 일련번호를 부여한 후, 첫 번째 표본을 임의로 선택하고 일정 간격하고 일정 간격으로 다음 표본을 선택
- 층화추출 : 모집단을 성격에 따라 몇 개의 집단 또는 층으로 나누고, 각 집단 내에서 원하는 크기의 표본을 무작위로 추출
- 군집 추출 : 모집단을 특성에 따라 여러 개의 집단으로 나누고 이들 집단 중에서 몇 개를 선택한 후, 선택된 집단 내에서 필요한 만큼의 표본을 임의로 선택
b. 비확률적 추출(nonprobability sampling)
: 확률이 정해져 있지 않거나 일부 개체가 선택될 가능성이 전혀 없는 경우
- 판단추출, 할당 추출, 편의 추출 → 연구자의 판단
(3) 자료의 종류 : 척도는 측정을 위해 부여한 숫자들 간의 관계를 의미
a. 명목척도(nominal scale) : 단순히 측정대상의 특성을 분류, 확인하기 위한 목적(예, 성별)
b. 서열(순위)척도(ordinal scale) : 단순히 크고 작고, 높고 낮음 등의 순위만 제공. 양적인 비교 불가(예, 선호 순위 등)
c. 등간척도(interval scale) : 순위를 부여하되 순위 사이의 간격이 동일하여 양적인 비교가 가능 (예, 온도계 수치, 물가지수)
d. 비율척도(ratio scale) : 절대 0점이 존재, 측정값 사이의 비율 계산이 가능(예, 몸무게)
2) 통계 분석
- 기술통계학(Descriptive statistics)
: 데이터 자체가 가진 정보를 정리하는 이론과 방법
- 추론통계학(Inferential statistics)
: 표본으로부터 모집단의 특성을 추론, 변수들 간의
함수 관계를 판단하는 이론과 방법
3) 확률 및 확률 분포
(참조 : https://drhongdatanote.tistory.com/49)
(1) 조건부 확률과 독립사건
: A사건이 일어났다는 조건 아래서 B사건이 일어날 조건부 확률 P(B|A) = P(A∩B)/P(A)
(2) 확률변수와 확률 분포
a. 확률변수와 확률 분포
: 일정한 확률을 갖고 발생하는 사건(event)에 수치가 부여되는 변수를 확률변수, 이 때 확률변수에 해당하는 함수 값이 확률 분포.
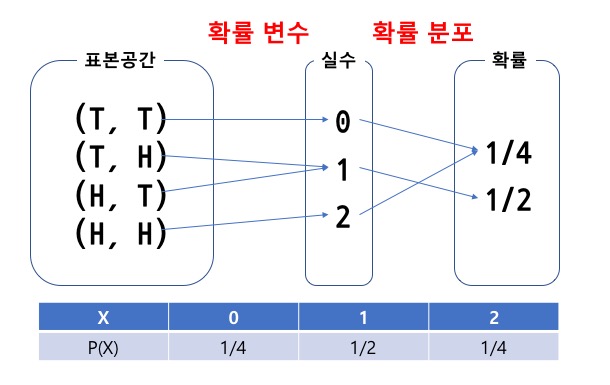
- 이산확률변수 : 변수가 취할 수 있는 값을 헤아려 열거할 수 있을 때, 확률 변수의 값이 떨어져 있을 때
- 연속확률변수 : 주어진 실수 구간 내에 속하는 어떠한 실수도 취할 수 있을 때
b. 결합확률분포 : 두 확률 변수, X, Y의 모든 값과 이에 대응하는 확률을 표나 그림으로 나타낸 것
- 이산형 확률분포 : 베르누이 확률분포, 이항분포, 기하분포, 다항분포, 푸아송 분포

- 연속형 확률분포 : 균일분포, 정규분포(카이제곱 분포, F분포)

(3) 확률변수와 기댓값과 분산
: 확률변수 X가 취하는 변화에 따라 확률값들은 분포를 이루게 되며 이러한 확률분포의 중심이 되는 평균을 기댓값이라 한다.
4) 추정과 가설검정
(1) 추정 : 모수의 값이 얼마인지 알아보는 점추정과 구간 추정으로 나뉨
* 좋은 추정량이 되기 위한 조건
① 불편성(unbiasedness)
: 치우침이 없는 성질, 추정량의 기대값이 모수에 일치하게 되는 통계량 → 불편추정량
② 효율성(efficiency)
: 추정량 분산이 작게 나타나는 성질 → 최소분산 추정량
③ 충족성(sufficiency)
: 표본 자료에 내재된 모든 정보를 활용할 수 있는 추정량, 효율성 → 충족성
④ 일관성(consistency) : 표본의 크기가 커짐에 따라 표본 오차가 작아져야 함
(2) 가설검정 : 모집단의 특성에 대한 통계적 가설을 모집단으로부터 추출한 표본을 사용해 검토하는 통계적 추론
(참고 : https://datascienceschool.net/view-notebook/897c3471597e42f0a17627953007780b/)

[출처]KS(한국)인증해설 통계와 확률 http://www.safetygo.com/
* 귀무가설(H0) : 기존에 받아들여지던 가설 /
대립가설(H1) : 연구자가 입증하려는 주장을 담은 가설
* 제1종오류(a error) : 귀무가설이 옳은데도 불구하고 귀무가설을 기각하게 되는 오류
예) 약이 효과가 없는데 있다고 하는 경우
* 제2종오류(b error) : 귀무가설이 옳지 않은데도 불구하고 귀무가설을 채택하는 오류
예) 약이 효과가 있는데 없다고 하는 경우
* 검정통계량(test statistics) : 관찰된 표본으로부터 구한 통계량으로, 그 확률분포가 모수에 의존함
* 유의확률(p-value) : 관측된 검정통계량의 값보다 더 대립가설을 지지하는 검정 통계량이 나올 확률,
귀무 가설이 사실이라는 가정하에 검정 통계량이 실제 실현된 숫자와 같거나 더 희귀한(rare) 값이 나올 수 있는 확률

* 유의수준(significance level)
: 귀무가설이 맞는데 잘못해서 기각할 확률의 최댓값(제1종오류), 보통 1%, 5%
* 기각역(critical region) : 검정 통계량의 분포에서 유의 수준 a의 크기에 해당되는 영역으로, 계산된 검정통계량의 유의성을 판정하는 기준
5) 비모수적 검정
(1) 모수적 검정
: 검정하고자 하는 모집단의 분포에 대해 가정을 한 뒤
관측된 자료를 이용해 구한 표본 평균, 표본 분산 등을 이용해 검정을 실시
(2) 비모수적 검정
: 모집단의 분포에 대해 아무 제약을 가하지 않고 검정을 실시하는 검정방법, 관측된 자료가 특정 분포를 따른다고 가정할 수 없는 경우 이용
a. 가설은 "분포의 형태가 동일", "분포의 형태가 동일하지 않다"와 같이 분포의 형태에 대해 설명
b. 관측값들의 순위나 두 관측값 사이의 부호 등을 이용해 검정
예) 부호 검정, 윌콕순의 순위합검정, 부호순위합검정, 만-위트니의 U검정, 스피어만의 순위상관계수
* 추론별 비교
2. 기초 통계분석
1) 회귀분석(Regression Analysis)
- 회귀분석 : 변수와 변수 사이의 관계를 알아보기 위한 통계적 분석 방법, 독립 변수의 값에 의하여 종속변수의 값을 예측하기 위함
(1) 선형회귀 모형
: X와 Y가 1차식으로 나타날 때 선형회귀모형이 됨
(2) 단순회귀모형 :
(3) 회귀모형 대한 가정
a. 선형성 (독립변수의 변화에 따라 종속변수도 변화하는 선형인 모형)
b. 독립성(잔차와 독립변수의 값이 관련되어 있지 않음)
c. 등분산성(오차항들의 분포는 동일한 분산을 갖는다)
d. 비상관성(잔차들끼리 상관이 없어야 한다)
e. 정상성(잔차항이 정규분포를 이뤄야 한다)
* 회귀분석 모형에서 확인해야 할 사항
① 모형이 통계적으로 유의미한가? → F분포값과 유의확률(p-value)
② 회귀계수들이 유의미한가? → 회귀계수의 t value과 유의확률(p-value)
③ 모형이 얼마나 설명력을 갖는가? → 결정 계수(R-squared)가 1에 가까울 수록 잘 설명함
④ 모형이 데이터를 잘 적합하고 있는가? → 잔차통계량(residuals)이 random하게 퍼질수록 최적모델, 회귀진단
* 회귀모델 적합성 검증 시 : summary( ) 함수를 통해 결정계수(R-squared), F통계량(F-statistic), 잔차의 표준오차(Residuals), 유의확률(p-value), 회귀계수(t-value) 등 정보를 알 수 있음
* 모델 진단 그래프
① Residuals VS Fitted : y축은 잔차를 보여줌. 선형회귀에서 오차는 평균이 0이고 분산이 일정한 정규분포를 가정(정상성), 기울기가 0인 직선이 이상적
② Normal Q-Q : 잔차가 정규분포를 따르고 있는 지 확인, 그래프가 선상에 있어야 함
③ Scale - Location : y축이 표준화 잔차를 나타냄. 기울기가 0인 직선이 이상적임
④ Cook's Distance : 1의 값이 넘어가면 관측치를 영향점(이상점)으로 판별
* 다중공선성 ? 다중회귀 시 모형의 일부 예측 변수가 다른 예측변수와 상관이 있을 때 발생하는 조건.
Vif 함수를 사용할 수 있으나, 보통 4넘으면 다중공선성이라고 명명.
(4) 최적회귀방정식 선택법
a. 종속변수 y에 영향을 미칠 수 있는 모든 설명변수 x들을 참여시킴
b. 데이터에 설명변수 x들의 수가 많아지면 관리하는데 어려움이 있으므로 가능한 범위 내에서 적은 수의 설명변수를 포함
(5) 설명변수를 선택하는 법
a. 모든 가능한 조합의 회귀분석
: 정합성을 측정해주는 지표 AIC(Akaike information criterion), BIC(Bayesian informaion criterion) 값이 작을 수록 좋다.
b. 단계별 변수 선택
- 후진 제거법(Backward) : 모든 변수가 포함된 모델에서 기준 통계치에 가장 도움이 되지 않는 변수를 하나씩 제거
- 전진 선택법(Forward) : 기준 통계치를 가장 많이 개선시키는 변수를 차례로 추가
* AIC는 아래 step( )함수 적용시 활용
* BIC는 leaps 패키지의 redsubsets( ) 이용 시 활용
2) 정규화 선형회귀
- 선형회귀계수에 대한 제약 조건을 추가함으로써 과적합(overfitting)을 막는 방법
3. 다변량분석
간단한 형식으로 데이터를 요약, 반응변수와 설명변수간의 관계를 쉽게 이해하기 위해 다변량 분석을 실시
1) 상관분석
- 데이터 내 두 변수 간의 관련성을 파악하는 방법
- 상관계수 : 두 변수간 관련성의 정도를 의미, 흔히 상관계수라 하면 피어슨 상관계수를 의미함
(1) 상관계수와 상관관계 : -1≤ 상관계수 r ≤+1
a. 상관계수 r이 1에 가까울 수록 상관이 높음
b. 상관계수 r이 0에 가까울 수록 상관이 낮음,
c. 상관계수 r=0 인 경우, 두 변수 사이에 직선적 상관관계가 없음을 의미하나, 어떤 관계도 존재하지 않는다는 뜻이 아님 따라서 산점도를 그려서 두 변수 간의 관계를 미리 알아보는 것이 중요함.
(2) 상관분석의 절차
a. 산점도를 통해 두 변수간의 대략적 관계를 파악
b. 상관계수에 필요한 통계량을 구함(공분산, 표준편차)
c. 상관계수를 구함
d. 모상관계수에 대한 유의성 검정
e. 결정계수를 구함
f. 상관계수와 결정계수를 제시하고 상관분석 결과 설명
* 상관계수 검정 : Cor.test( )함수를 사용, p-value가
0.05보다 작은 경우 상관관계가 유의한 것으로 나타남
(3) 피어슨의 상관계수 vs 스피어만 상관계수 차이
(4) 결정계수 : R2=회귀제곱합/총제곱합
(총제곱합(SST) = 회귀제곱합(SSR)+오차제곱합(SSE))
결정계수 값이 클수록 회귀방정식의 적합도와 변수간의 상관관계를 더 잘 설명해줌.
2) 다차원 척도법(MDS, Multidimensional Scaling)
: 개체들 사이의 유사성/비유사성을 유클리디안 거리를 통해 측정하여 2차원 또는 3차원 공간상에 표현하는 분석 방법. cmdscale( )함수를 사용함
3) 주성분 분석(PCA, Principal Component Analysis)
: 데이터에 많은 변수가 있을 때 변수의 수를 줄이는 차원 감소 기법. 변수들 간에 내재하는 상관관계 및 연관성을 이용해 소수의 주성분으로 차원을 축소하는 분석기법
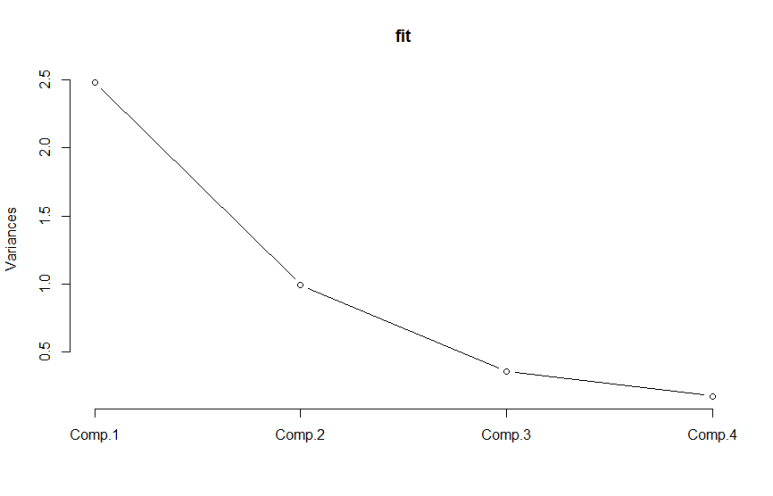
* 스크리도표(Scree plot)
: 각 요인의 eigenvalue를 그림으로 보여주는 것으로 추출할 요인의 수를 결정하는데 사용 됨. 1보다 작은 값은 요인으로서 의미가 없다는 뜻.
* 주성분 분석 vs 공통요인분석
- 주성분 분석 : 데이터 정보의 손실을 최소화해서 단순히 데이터를 축소하는 방법
- 공통 요인 분석 : 자료의 축소 + 데이터에 내재적 속성 파악
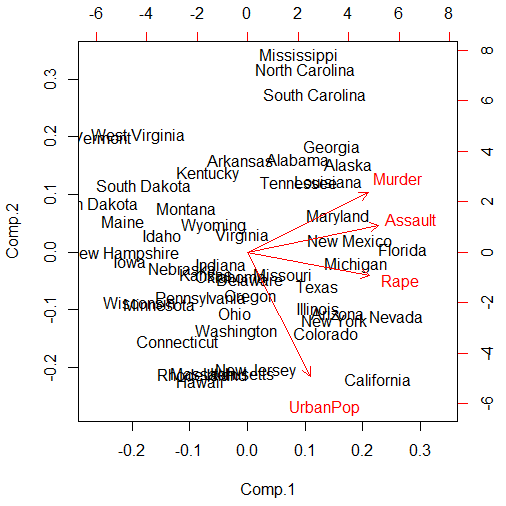
* biplot( ) 함수 : 제1주성분과 제2주성분만을 구해 2차원의 점 그래프로 표현. 주성분에 대한 고유벡터와 자료별 주성분 점수를 좌표로 나타내어 주성분과 자료 간의 관계를 파악할 수 있음
4. 시계열 예측
관측치가 시간적 순서를 가지며, 시계열 분석의 주요 목적은 미래 값을 예측하고 시간에 따른 데이터 특성을 파악
1) 정상성(Stationary)
: 시계열의 수준과 분산에 체계적인 변화가 없다. 즉 주기적 변동이 없다는 의미로 미래는 확률적으로 과거와 동일하다는 것을 뜻함.
* 정상시계열의 특징
a. 시간 t에 관계없이 평균값이 일정

b. 시간 t에 관계없이 분산이 일정

c. 두 지점의 공분산이 시간 t가 아닌, 시차와 연관됨

- 위 세가지 특징을 만족하지 못하면 비정상 시계열
2) 비정상시계열 → 정상시계열 전환법
* 시계열 데이터의 종류
- 백색잡음 : 추세와 분산이 커지는 시계열.
대표적인 정상시계열임. 평균과 분산이 일정하며 자기공분산(특정 시차의 길이를 갖는 것)이 0인 시계열.
- 추세를 갖는 시계열 : 평균이 변화하는 시계열
- 랜덤위크 시계열 : 분산이 변화하는 시계열
(1) 평균이 일정하지 않은 경우 : 기존 시계열 데이터에 차분을 하면 정상 시계열이 됨. diff(data)
(2) 계졀성을 갖는 비정상 시계열의 경우 : 계절차분
diff(data, s)
(3) 분산이 일정하지 않은 경우 : 기존 시계열 데이터에 자연로그를 취하면 정상 시계열이 됨. log(data)
* 자기상관 : 시점 t와 시점(t-1)간의 상관관계를 의미.
일정 기간 증가하거나 감소하는 경우 자기상관이 존재.
3) 시계열 모형
(1) 자기회귀모형 (AR, AutoRegressive)
: 자기상관성을 시계열 모형으로 배열
예) 8일 판매량 = 가중치x7일 판매량 + 오차(백색잡음), 과거 1시점 이전 자료만 영향을 준다면 AR(1)모형, 즉 1차 자기회귀모형이라고 함.
- Yt=a * Yt-1 + εt (오차)
(2) 이동평균모형 (MA, Moving Average)
- 시간이 지날수록 변수의 평균값이 지속적으로 증감하는 경향에 대한 이동평균을 시계열 모형으로 구성
- 최근 데이터의 평균을 예측치로 사용하여 현시점의 자료를 유한개의 백색잡음의 선형결합으로 표현. 항상 정상성을 만족함.
- Yt= εt (현 오차) - b * εt-1(바로 전 오차)
(3) 자기회귀이동평균모형 (ARMA)
- 자기회귀모형 + 이동평균모형 으로 정상성을 만족함
- 부분자기상관함수(PACF)와 자기상관함수(ACF)를 통해 차수를 선정할 수 있음
- 부분자기상관 함수 pacf( )를 통해 AR 차수 확인 : p+1부터 절단됨
- 자기상관함수 acf( )를 통해 MA 차수를 확인 : q+1부터 절단됨

[출처]minitap support, AR(1)모형
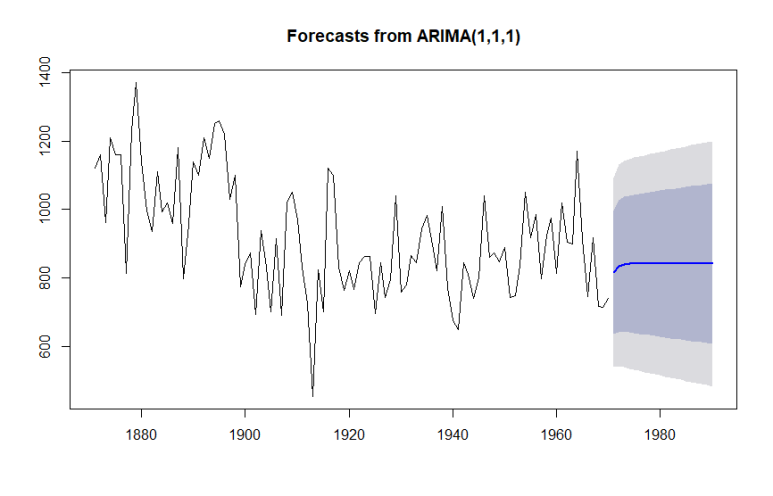
(4) 자기회귀누적이동 모형 (ARIMA)
- 비정상시계열 모형으로 차분이나 변환을 통해 AR, MA, ARMA 모형으로 정상화
- ARIMA(p,d,q)로 AR(p), MA(q), d는 몇 번 차분했는지를 의미함. d=0이면 ARMA 모형임
- auto.arima( )함수를 통해 적절한 차수 결정
(5) 분해 시계열 : 시계열에 영향을 주는 일반적인 요인을 분리해 분석하는 방법
a. 추세요인 : 자료가 어떤 특정한 형태를 취할 때
b. 계절요인 : 계절에 따라, 고정된 주기에 따라 자료가 변화할 경우
c. 순환요인 : 알려지지 않은 주기를 가지고 자료가 변화할 때
d. 불규칙요인 : 위 세 가지 요인으로 설명할 수 없을 때
* decompose(data) 함수를 사용해 시계열 데이터를 위 4가지 요인으로 분리할 수 있음
예) decompose(data)$trend ( 또는 seasonal )
'데이터분석 > 데이터분석준전문가(ADsP)' 카테고리의 다른 글
| ADsP 대비 Part3.정형 데이터마이닝 (0) | 2019.05.16 |
|---|---|
| ADsP 대비 Part3.R기초와 데이터 마트 (1) | 2019.05.13 |
| ADsP 대비 Part2.분석 마스터플랜 (0) | 2019.05.13 |
| ADsP 대비 Part2.데이터 분석 기획의 이해 (0) | 2019.05.12 |
| ADsP 대비 Part1.가치창조를 위한 데이터 사이언스와 전략 인사이트 (0) | 2019.04.04 |




댓글